|
OGRE 2.1
Object-Oriented Graphics Rendering Engine
|
|
OGRE 2.1
Object-Oriented Graphics Rendering Engine
|
Names no longer need to be unique and are optional (ie. two SceneNodes can have the same name). To identify uniqueness, classes derive from IdObject, and use IdObject::getId()
Note that, for example, Entities are completely different from SceneNodes (they don't even share a common base class), so it is possible for an Entity and a SceneNode to have the same Id.
You won't find two Entities (or rather, two MovableObjects) with the same Id. Otherwise it's a bug.
This change quite affect the creation calls. For example it's quite common to see this snippet:
However the new definition of create Entity is as follows:
In other words, your old snippet will try to look for the mesh myEntityName in the group meshName.mesh; which will probably fail. To port to Ogre 2.0; one would just need to write:
All relevant data that needs to be updated every frame is stored in SoA form (Structure of Arrays) as opposed to AoS (Arrays of Structures)
This means that data in memory instead of being placed like the following:
It is layed out as the following
However our setup is actually quite different from other engines approaches, as 4 Vector3s are packed like the following in memory:
| Vectors [0; 4) | Vectors [4; 8) |
|---|---|
| XXXX YYYY ZZZZ | XXXX YYYY ZZZZ |
Debugging SIMD builds can be quite counterintuitive at first, in which case defining OGRE_USE_SIMD 0 and recompiling will force Ogre to use the C version of ArrayMath, and hence only pack 1 Vector3 per ArrayVector3.
Nevertheless, debugging SSE builds directly isn't that difficult. MovableObjects store their SoA data in MovableObject::mObjectData. The following screenshot shows it's contents:
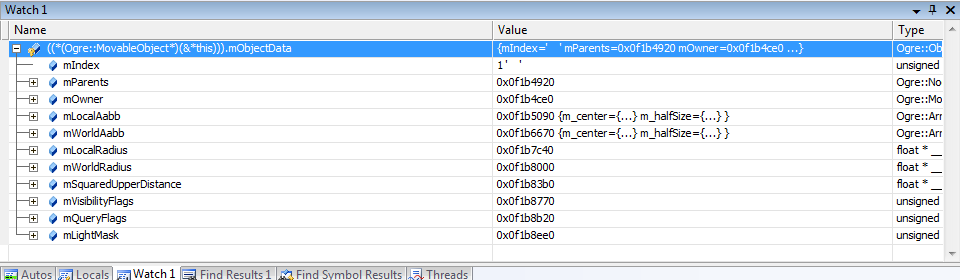
The most important element in this picture is mIndex. Because this was taken from a SSE2 (single precision) build, its value can range between 0 and 3 (inclusive). The macro ARRAY_PACKED_REALS is defined as 4 for this build to let application know how many floats are being packed together.
In this case, ObjectData::mParents contains the parent nodes of all four MovableObject. In this case our parent is in mObjectData.mParents[1]; because mIndex = 1

In the picture above, we can now inspect the parent node of our object. Note that in the watch window adding a comma followed by a number forces MSVC debugger to interpret the variable as an array. Otherwise it may only show you the first element alone. Example: mObjectData.mParents,4
The following is part of the declaration of Transform (which is used by Nodes):
When ARRAY_PACKED_REALS = 4 (i.e. SSE builds), though not strictly correct, we could say mParents is declared as:
Hence to know which mParents belongs to us, we have to look at mParents[mIndex].
Same happens with mInheritOrientation. When 9 consecutive Nodes are created, if we take a look at mParents pointers, we would notice that first 4 point to the same memory location:
The Transform of the first 4 Nodes will have exactly the same pointers; the only difference is the content of mIndex. When we go to the 5th, the pointers increment by 4 elements. mIndex is used to determine where our data really is. This layout may be a bit hard to grasp at first, but it's quite easy once you get used to it. Notice we satisfy a very important property: all of our pointers are aligned to 16 bytes.
ArrayVector3, ArrayQuaternion and ArrayMatrix4 require a bit more of work when watching them through the debugger:
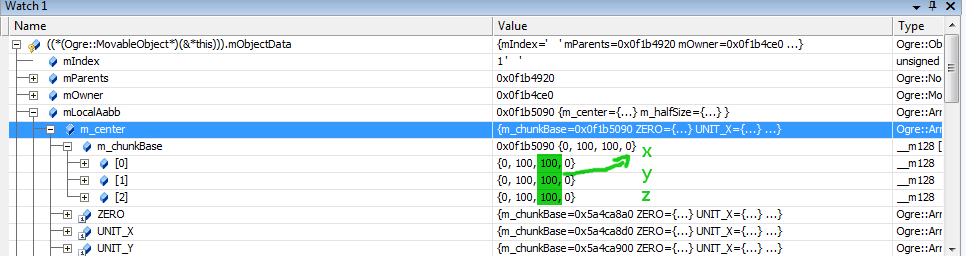
Here the debugger is telling us that the center of the Aabb in local space is at (100; 100; 100). We're reading the 3rd column because mIndex is 1; if mIndex were 3; we would have to read the 1st column.
m_chunkBase[0] contains four XXXX which are read right to left.
m_chunkBase[1] contains four YYYY, ours is the second one (starting from the right)
m_chunkBase[3] you should've guessed by now contains ZZZZ
Note that if, for example, the 4th element (in this case it reads (0, 0, 0)) is an empty slot (i.e. there are only 3 entities in the entire scene); it could contain complete garbage; even NaNs. This is ok. We fill the memory with valid values after releasing memory slots to prevent NaNs & INFs; as some architectures are slowed down when such floating point special is present; but it is possible that some of them slip through (or it is also possible a neighbour Entity actually contains an infinite extent, for example).
Is m_chunkBase a transform matrix? NO. In SSE2 SIMD builds, ArrayVector3 packs 4 vectors together (because ARRAY_PACKED_REALS = 4). If 4 Nodes are created named A, B, C, D; the picture above is saying:
m_chunkBase[0] = { D.x, C.x, B.x, A.x }m_chunkBase[1] = { D.y, C.y, B.y, A.y }m_chunkBase[2] = { D.z, C.z, B.z, A.z }So, to know the contents of B, you need to look at the 3rd column.
Seeing a null pointer in ObjectData::mParents[4] is most likely a bug unless it's temporary. During SoA update; those memory slots that were not initialized (or whose MovableObjects haven't been attached to a SceneNode yet) are set to a dummy pointer owned by the MemoryManager instead of setting to null.
This prevents us from checking that the pointers are null every time we need access to them in SoA loops (which are usually hotspots); with the associated branch misspredictions that may be associated. This is a pattern in Data Oriented Design.
Note however, that MovableObject::mParentNode is null when detached (since it isn't a SoA variable) while MovableObject::mObjectData::mParents[mIndex] points to the dummy node. When attached, both variables will point to the same pointer.
Same happens with other pointers like ObjectData::mOwner[] and Transform::mParents[]
In Ogre 1.x an object "was in the scene" when it was attached to a scene node whose ultimate parent was root. Hence a detached entity could never be displayed, and when attached, calling setVisible( false ) would hide it.
In Ogre 2.x, objects are always "in the scene". Nodes just hold position information, can be animated, and can inherit transforms from their parent. When an Entity is no longer associate with a node, it hides itself (setVisible( false ) is implicitly called) to avoid being rendered without a position. Multiple entities can share the same position, hence the same Node.
This means that when attaching/detaching to/from a SceneNode, the previous value of MovableObject::getVisible is lost. Furthermore, calling setVisible( true ) while detached is illegal and will result in a crash (there is a debug assertion for this).
Due to how slow was Ogre 1.x in traversing SceneNodes (aka the Scene Graph), some users recommended to detach its objects or remove the SceneNode from its parent instead of calling setVisible( false ); despite the official documentation stating otherwise.
In Ogre 2.x this is no longer true, and we do a significant effort to keep updates and iterations as fast as possible. This may have in turn increased the overhead of adding/removing nodes & objects. Therefore hiding objects using setVisible is much more likely to be orders of magnitude faster than destroying them (unless they have to be hidden for a very long time)
Unless hidden (see Attachment and Visibility), all MovableObejcts like Entities, InstancedEntities, Lights and even Cameras require being attached to a SceneNode; since Nodes are the beholders of the transform (position and rotation).
There are no node-less Lights anymore. Their transform data is in the Nodes as it works perfectly with the optimized, streamlined functions (particularly update derived bounding box for computing visibility) and have no longer their own position and direction; which is now hold by the Node.
Another reason for this decision is that combining the transform data from the node with the Light's was inefficient, while the overhead of using the additional Node is virtually eliminated in Ogre 2.0; and furthermore it works better for lights that require more than direction, but a full quaternion (e.g. textured spot lights and area lights).
Functions like Light::getDirection and Light::setDirection will redirect to the scene node, and fail when not attached. Lights when created aren't attached to a SceneNode, so you will have to attach to one first before trying to use it.
Cameras do however have their own position and rotation for simplicity and avoid breaking older coder so much (unlike Lights). Performance wasn't a concern since it's normal to have less than a dozen cameras in a scene, compared to possibly thousands of lights. By default cameras are attached to the root scene node on creation.
Therefore if your application was attaching Cameras to SceneNodes of your own, you will have to detach it first calling Camera::detachFromParent; otherwise the engine will raise the well-known exception that the object has already been attached to a node.
In the past, obtaining the derived position was a matter of calling SceneNode::_getDerivedPosition. Ogre would keep a boolean flag to know if the derived transform was dirty or not. Same happened with orientation and scale.
Ogre 2.0 removed the flag has for the sake of performance[^1] (except for debug builds which use a flag for triggering assertions).
The following functions will use the last cached derived transform without updating:
Node::_getDerivedPositionNode::_getDerivedOrientationNode::_getDerivedScaleWhat this means that the following snippet won't work as expected, and will trigger an assert in debug mode:
All derived transforms are efficiently updated in SceneManager::updateAllTransforms which happens inside updateSceneGraph. You should start using the derived transforms after the scene graph has been updated. Users can have fine-grained control on when the scene graph is updated by manually implementing (or modifying) Root::renderOneFrame
Nonetheless, if the number of nodes that need to be up to date is low, users can call the "Updated" variants of these functions:
Node::_getDerivedPositionUpdatedNode::_getDerivedOrientationUpdatedNode::_getDerivedScaleUpdatedThese functions will force an update of the parents' derived transforms, and its own. It is slower and not recommended for usage of a massive number of nodes. If such thing is required, consider refactoring your engine design to require the derived transforms after SceneManager::updateAllTransforms.
The following snippet demonstrates how to use updated variants:
MovableObject's world Aabb & radius follows the same pattern and subject to the same issues.
Both MovableObjects[^2] and Nodes have a setting upon creation to specify whether they're dynamic or static. Static objects are meant to never move, rotate or scale; or at least they do it infrequently.
By default all objects are dynamic. Static objects can save a lot of performance on CPU side (and sometimes GPU side, for example with some instancing techniques) by telling the engine they won't be changing often.
SCENE_STATIC won't update their derived position/rotation/scale every frame. This means that modifying (eg) a static node position won't actually take effect until SceneManager::notifyStaticDirty( mySceneNode ) is called or some other similar call that foces an update.If the static scene node is child of a dynamic parent node, modifying the dynamic node will not cause the static one to notice the change until explicitly notifying the SceneManager that the child node should be updated.
If a static scene node is child of another static scene node, explicitly notifying the SceneManager of the parent's change automatically causes the child to be updated as well.
Having a dynamic node to be child of a static node is perfectly plausible and encouraged, for example a moving pendulum hanging from a static clock. Having a static node being child of a dynamic node doesn't make much sense, and is probably a bug (unless the parent is the root node).
Static entities are scheduled for culling and rendering like dynamic ones, but won't update their world AABB bounds (even if their scene node they're attached to changes) Static entities will update their aabb if user calls SceneManager::notifyStaticDirty( myEntity ) or the static node they're attached to was also flagged as dirty. Note that updating the node's position doesn't flag the node as dirty (it's not implicit) and hence the entity won't be updated either.
Static entities can only be attached to static nodes, and dynamic entities can only be attached to dynamic nodes.
On most cases, changing a single static entity or node (or creating more) can cause a lot of other static objects to be scheduled to update, so don't do it often, and do it all in the same frame. An example is doing it at startup (i.e. during loading time)
Entities & Nodes can switch between dynamic & static at runtime by calling setStatic. However InstancedEntities can't.
You need to destroy the InstancedEntity and create a new one if you wish to switch (which, by the way, isn't expensive because batches preallocate the instances) InstancedEntities with different SceneMemoryMgrTypes will never share the same batch.
Attention #1!
Calling
SceneNode::setStaticwill also force a call toMovableObject::setStaticto all of its attached objects. If there are objects you wish not to switch flags, detach them first, and then reattach. If there are InstancedEntities attached to that node, you have to detach them first as they can't directly switch between types. Otherwise the engine will raise an exception.Attention #2!
Calling
setStatic( true )when it was previously false will automatically callnotifyStaticDirtyfor you.
Q: Do the changes mean that you can set a "static"-flag on any entity and it automatically gets treated as static geometry and the batch count goes down when there are many static entities sharing the same material?
A: No and yes. On normal entities, "static" allows Ogre to avoid updating the SceneNode transformation every frame (because it doesn't change) and the AABB bounds from the Entity (because it doesn't change either). This yields massive performance bump. But there is no batch count going down.
When using Instancing however, we're already batching everything together that has the same material, so it is indeed like Static Geometry, except that we cull per instance basis (which puts a bit more strain on CPU, but allows for very fine grained frustum culling for the GPU, giving it less work), and 2.0's culling code is several times faster than 1.9's.
When using normal entities, batch count won't go down when using the "static" flag. However it will greatly improve performance compared to 1.9, because we're skipping the scene node transform & AABB update phases, and that takes a lot of CPU time.
If you get assertions that mCachedAabbOutOfDate or mCachedTransformOutOfDate are true, they mean mean that the derived world AABB wasn't updated but was attempted to be used, or that the derived transform[^3] was out of date and an attempt to use it was made; respectively.
They can trigger for various reasons:
Nodes/Objects are of type SCENE_STATIC and their data changed (i.e. you called setPosition) but no call to SceneManager::notifyStaticDirty was made.
Solution: Call SceneManager::notifyStaticDirty, or use a function that implicitly calls that function.
You've manually modified their data (i.e. you called setPosition) after SceneManager::updateAllTransforms or SceneManager::updateAllBounds happened; most likely through a listener.
Solutions:
updateAllTransforms.Node::_getFullTransformUpdated or MovableObject::getWorldAabbUpdate after modifying the object to force a full update on that node/entity only. You only need to call these functions once, and its transform will be updated and cached; if you keep calling the "Updated" variations, you're just going to eat CPU cycles recalculating the whole transform every time.updateAllTransforms/updateAllBounds again.It's a bug in Ogre. Because the refactor was very large, some components still try to modify nodes and movables after the call to updateAllTransforms/updateAllBounds.
Solution: Report the bug to JIRA. When we get to refactor that faulty component, the node will be touched before the call to updateAllTransforms, but if the component isn't yet scheduled for refactor we might just fix it by calling getDerivedPositionUpdated
In Ogre 1.x; advanced users could submit or inject Renderables directly to the RenderQueue without the need of a MovableObject. This was possible because there was redundancy (both classes duplicated the same data), or Renderable used virtual functions to query data from the MovableObject (which advanced users could overload to submit this data directly instead of relying on a MO).
Since Ogre 2.x; a Renderable must have a MovableObject linked to it, as RenderQueue's addRenderable function requires two parameters, one for the MovableObject, another for the Renderable. Providing a null pointer as the MovableObject will likely result in a crash.
Multiple Renderables can still share the same MovableObject though and implementations don't have to derive from both at the same time either.
For objects that are part of the scene, Ogre 1.x employed the visitor pattern to query all the Renderables that a MovableObject contained. In Ogre 2.x; this pattern was removed.
Ogre users implementing their own classes that derive from MO must populate the MovableObject::mRenderables vector instead; which the SceneManager will access directly to add the renderables to the RenderQueue.
The reason behind this change is performance. The visitor pattern is too costly for this task.
Once you have the Mesh pointer, get the Submesh. Then grab the Vao:
There is one Vao per LOD level. Note that multiple LODs may share the same vertex buffers:
From there you can get the vertex declaration for each vertex buffer:
The v1 interface allowed to explicitly specify this data. However this can be automatically calculated:
The offset can be automatically calculated from the previous element's size. The index parameter can also be automatically calculated by counting the numbers of elements already in the array. And the source can be arranged by having an array of vertex elements.
The following code is equivalent, v1 vs v2 format:
This method is more convenient as users often messed up the offset argument (i.e. forgot to update it), and more compact too. After all it's just an std::vector container. The only gotcha is that the order in which elements are inserted into the vector is now relevant.
You can use the static function VaoManager::calculateVertexSize( const VertexElement2Vec &vertexElements ) to calculate the vertex size in bytes that a declaration vector is holding.
RenderWindow through the configuration, this snippet can force it:If you're manually creating the RenderWindow, then you need this snippet:
PBS expects gamma correction, otherwise it won't look right.
Even the colours are different, as real life values should be used. A white material of RGB (1.0, 1.0, 1.0) means an incredibly bright material. Not even paper is so white.
PBS also work best with HDR pipelines because real life values means the sun has a colour power in the tens thousands of lums (see also Crytek's reference; see Frostbite's slides starting 35). Of course without HDR, a sun power that bright would definitely overflow a regular 32-bit RGBA render target.
Colour values need to be calibrated, see Unity's, Sebastien Lagarde's (more) and FarCry's (more from FarCry).
Even textures may need to be tweaked, see Crytek's slides (slide 56) about what constitutes a "good" diffuse texture and a "bad" diffuse texture (should contain barely any self shadowing; detail is given by the gloss map and a very strong normal map that usually looks bad if look through 3DS Max or Maya). This is a common cause for scenes to look "dull" and lifeless.
Bottom line, this is an art problem, not a technical one.
PI for correctness. If you're using an LDR pipeline instead of an HDR one; set the light's power (Light::setPowerScale) to PI (3,14159265...) to compensate.The HlmsTextureManager will load diffuse textures w/ gamma correction to avoid the problem.
However if you're loading them via external means (i.e. using the regular TextureManager; for example CEGUI) you will need to load them with gamma correction explicitly.
[^1]: This is a performance optimization. For a reasoning behind this, read the Ogre 2.0 design slides.
[^2]: i.e. Entities, InstancedEntities
[^3]: Derived position, orientation, scale or the 4x4 matrix transform.